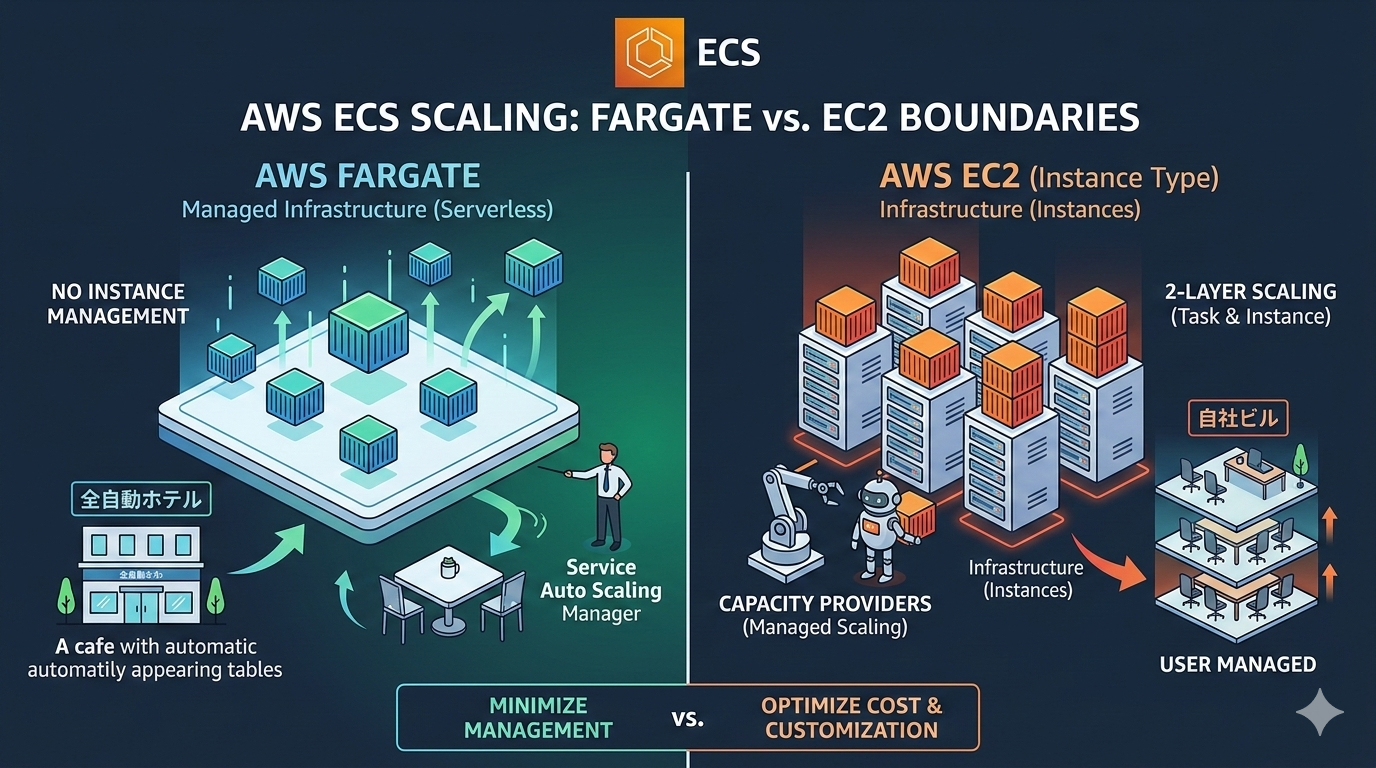
AWSでコンテナを運用する際、最も重要なのが「スケーリング」の設計です。「Fargateは楽、EC2は大変」というイメージの裏側に、具体的にどのような仕組みの違いがあるのか。基本から実務で必須となる「Capacity Provider」の高度な設定まで、丁寧に解説します。
結論
FargateとEC2、それぞれのスケーリング管理の境界線は以下の通りです。
| 起動タイプ | 基盤(インフラ)のスケーリング | ECSタスクのスケーリング |
|---|---|---|
| ECS on Fargate | 不要(AWSがフルマネージド) | 必要(Service Auto Scalingを使用) |
| ECS on EC2 | 必要(Auto Scaling Groupを使用) | 必要(Service Auto Scalingを使用) |
ポイント)
ECS on EC2では「タスク」と「基盤(EC2)」の2重のスケーリング管理が必要になる、という点が最大の相違点です。
認識)ECS on Fargate と ECS on EC2 の構成の違い

現場の司令塔:Service Auto Scaling(SAS)
基盤がどちらであっても、ECSタスクの数を増減させるのは「Service Auto Scaling」の役割です。この設定には、主に2つの戦略があります。
- ターゲット追跡スケーリング(Target Tracking)
「エアコンの温度設定」のようなイメージです。- 仕組み:「平均CPU使用率を70%に保って」と設定するだけで、AWSが逆算してタスクの数を自動調整します。
- メリット:設定が非常にシンプル。ほとんどのケースではこれで十分かと思います。
- スケールアウト/イン判断基準のメトリクス:
- ECSServiceAverageCPUUtilization
サービスの平均 CPU 使用率 - ECSServiceAverageMemoryUtilization
サービスのメモリ平均使用率 - ALBRequestCountPerTarget
Application Load Balancer ターゲットグループ内の ターゲットごと に完了したリクエストの数
- ECSServiceAverageCPUUtilization
- ステップスケーリング(Step Scaling)
「マニュアル車のギアチェンジ」のようなイメージです。- 仕組み: 「CPUが70%を超えたら2個追加、80%を超えたらさらに5個追加」と、段階的なルールを定義します。
- メリット: 負荷の急増に対して「一気に大量のタスクを増やす」といった、細かい制御が可能です。
- スケールアウト/イン判断基準のメトリクス:
- ECSServiceAverageCPUUtilization
サービスの平均 CPU 使用率 - ECSServiceAverageMemoryUtilization
サービスのメモリ平均使用率
- ECSServiceAverageCPUUtilization
知っておくべき知識:CPUなどの使用率の正体
SASが見ているのは、サービス内の全タスクの平均値です。
例)
平均使用率 = 全タスクの実使用CPU合計 ➗ 全タスクの予約CPU合計 ✖️ 100
特定のタスクだけに負荷が偏っている場合は、全体の平均がしきい値を超えない限りスケールアウトしない可能性があるため、ロードバランサーでの均等な分散が重要になります。
EC2の「2重スケーリング」を解決する3つの設定の違い
EC2を基盤にする場合、タスクが増えても「それを載せるEC2」が足りなければエラーになります。この「インフラ側の管理」を自動化し、Fargateに近い運用感を実現するのがCapacity Providersの以下の機能です。
- Managed Scaling(マネージド型スケーリング)
「タスクを増やしたいのに、EC2に空きがない!」という状況を検知し、裏側のAuto Scaling Group(ASG)を自動で動かしてEC2を補充します。 - Managed Instance Termination Protection(終了保護)
スケーリングで「EC2を減らす」とき、「まだ仕事中のタスクが載っているEC2」が勝手に消されるのを防ぎます。 安全なスケールインには必須の設定です。 - Managed Draining(マネージド型ドレイニング)
EC2を入れ替える際などに、「今載っているタスクを、別の健康なインスタンスへ安全に引っ越しさせる」機能です。リクエスト処理中のタスクを強制終了させず、優しく「退去」させてからインスタンスを停止させます。
Fargateの場合:スケーリング設定は不要、でも「戦略」は必要
Fargateには「EC2インスタンス」という概念がないため、先ほどのスケーリングや終了保護の設定は不要です。しかし、FargateにもCapacity Providerの設定があるのは、「コストと信頼性のバランス(戦略)」を決めるためです。
- FARGATE:信頼性重視(システムの継続)
- FARGATE_SPOT:コスト重視(最大70%オフだが、中断の可能性あり)
これらを組み合わせ、「基本の2個は通常タイプ、増える分はスポットを8割使う」といった重量(Weight)ベースの配分ができるのが、FargateにおけるCapacity Providerの役割です。
AWS Fargate の料金
https://aws.amazon.com/jp/fargate/pricing/
まとめ
| 項目 | Fargate | EC2 (Capacity Provider活用) |
|---|---|---|
| タスクのスケーリング | SASで自動化 | SASで自動化 |
| インフラの補充 | 不要(AWSが管理) | Managed Scaling で自動化 |
| 安全な撤去 | 不要 | Termination Protection / Draining |
| OSの運用管理 | 不要(フルマネージド) | 必要(ユーザー責任) |
最後に
「EC2 = 管理が大変」という認識は正しいですが、今回紹介した機能をフル活用することで、「スケーリングの苦労」はFargateと遜色ないレベルまで下げることができます。
- 運用コストを最小化したい → Fargate
- インスタンスコストを抑えつつ、運用を自動化したい → EC2 + Capacity Providers
それぞれの特徴を理解して、プロジェクトに最適な基盤を選んでいきましょう!
参考記事(AWS公式)
- AWS Fargate: A Product Overview
https://aws.amazon.com/jp/blogs/compute/aws-fargate-a-product-overview/ - Introducing Cloud Native Networking for Amazon ECS Containers
https://aws.amazon.com/jp/blogs/compute/introducing-cloud-native-networking-for-ecs-containers/ - Amazon ECS サービスを自動的にスケールする
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/service-auto-scaling.html - AWS Fargate on Amazon ECS のタスクの廃止とメンテナンス
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task-maintenance.html

コメント